
Projektēšana mērogā Metodes, kā likt lielajiem datiem veikt jūsu lietotājiem
- Projektēšana mērogā Metodes, kā likt lielajiem datiem veikt jūsu lietotājiem
- II. Kas ir lielie informācija?
- III. Lielo informācijas izaicinājumi
- IV. Lielu informācijas projektēšana mērogā
- V. Informācijas garāža lielajiem datiem
- 6. Problēma Risinājums
- VII. NoSQL informācijas bāzes lielajiem datiem
- Hadoop un Spark lielajiem datiem
- IX. Lielo informācijas pētījuma straumēšana

II. Kas ir lielie informācija?
III. Lielo informācijas izaicinājumi
IV. Lielu informācijas projektēšana mērogā
V. Informācijas garāža lielajiem datiem
VI. Informācijas ezeri lielajiem datiem
VII. NoSQL informācijas bāzes lielajiem datiem
VIII. Hadoop un Spark lielajiem datiem
IX. Lielo informācijas pētījuma straumēšana
Biežāk uzdotās problēmas
| Priekšmets | Kalpot kā |
|---|---|
| Lielie informācija | Lielas informācijas kopas, kas ir vienkārši pārāk sarežģītas tradicionālajām informācijas apstrādes metodēm |
| Informācijas zinātne | Zinātnisku metožu, procesu, algoritmu un sistēmu lietošana informācijas un ieskatu pirkšanai no datiem |
| Lietotāja zināšanas | Lietotāja mijiedarbības izmantojot preču par to, ja pakalpojumu standarts |
| Pie lietotāju orientēts dizains | Dizaina iegūt piekļuvi, kas specializējas lietotāja vajadzībām |
| Izmērs | Tehnikas iespēja risināt arvien lielāku informācijas par to, ja lietotāju apjomu |

II. Kas ir lielie informācija?
Lielie informācija ir termins, ko lieto, kā veids, kā aprakstītu lielo informācijas apjomu, ko ģenerē korporācijas, organizācijas un privātpersonas. Šīs zināšanas var arī atgriezties no pārāk daudzskaitlīgiem avotiem, kā piemērs, sociālajiem medijiem, tiešsaistes darījumiem un sensoriem. Lielos datus nepārtraukti raksturo to daudzums, ātrums un diezgan daudz.
Lielo informācijas daudzums paplašinās eksponenciāli, un notiek lēsts, ka līdz 2025. gadam nozare ģenerēs 175 zettabaitus informācijas. Šo izaugsmi veicina arvien pieaugošā savienoto ierīču lietošana, sociālo mediju paplašināšanās un arvien pieaugošā uzņēmumu digitalizācija.
Paplašinās papildus lielo informācijas pārraides ātrums. Tas var būt drošs izmantojot faktu, ka informācija notiek ģenerēti reāllaikā, un tas ir ļoti svarīgi pierādīt spēju negaidīti risināt šos datus, kā veids, kā pieņemtu pārdomātus lēmumus.
Paplašinās papildus lielo informācijas šķirne. Tas var būt drošs izmantojot faktu, ka informācija notiek vākti no pārāk daudzskaitlīgiem avotiem, kā piemērs, strukturētiem datiem, nestrukturētiem datiem un daļēji strukturētiem datiem.
Lielie informācija ir problēma korporācijām, ņemot vērā tos varētu būt sarežģīts kontrolēt un pētīt. Alternatīvi lielie informācija varētu būt papildus lolots priekšrocība korporācijām, ņemot vērā tos var arī gūt labumu, kā veids, kā uzlabotu izvēļu pieņemšanu, noteiktu jaunas varbūtības un radītu jaunus produktus un pakalpojumus.
III. Lielo informācijas izaicinājumi
Lielo informācijas izaicinājumi ir liels skaits un diezgan daudz. Tajos ietilpst:
- Daudzums: ģenerēto informācijas daudzums paplašinās eksponenciāli. 2024. katru gadu uz šīs planētas tika ģenerēti 44 zettabaiti informācijas, un paredzams, ka šis atlase līdz 2025. gadam pieaugs līdz 181 cetabaitam.
- Ātrums: palielināsies papildus informācijas ģenerēšanas ātrums. Iepriekšējais informācija tika ģenerēti relatīvi lēni. Alternatīvi šobrīd informācija notiek ģenerēti izmantojot saules gaismas ātrumu.
- Kategorija: palielināsies papildus ģenerējamo informācijas šķirņu veidi. Iepriekšējais informācija būtībā kādreiz bija strukturēti informācija. Alternatīvi pašlaik informācija notiek ģenerēti papildus nestrukturētos formātos, kā piemērs, tekstā, attēlos un filmas.
- Realitāte: Informācijas standarts varētu būt problēma. Iepriekšējais tika it kā, ka informācija ir kā tam vajadzētu būt un uzticami. Alternatīvi pašlaik informācija nepārtraukti vien ir nepilnīgi, neprecīzi un neobjektīvi.
Šīs jautājumi apgrūtina lielo informācijas pārvaldību, uzglabāšanu un analīzi. Alternatīvi ir dažādība atbildes, ko var arī gūt labumu, kā veids, kā risinātu šīs jautājumi.
Kā piemērs, informācijas pārvaldības risinājumus var arī gūt labumu lielo informācijas organizēšanai un strukturēšanai. Informācijas uzglabāšanas risinājumus var arī gūt labumu, kā veids, kā saglabātu lielus datus rentablā un mērogojamā kaut kādā veidā. Un informācijas pētījuma risinājumus var arī gūt labumu, kā veids, kā gūtu ieskatu no lielajiem datiem.
Risinot lielo informācijas jautājumi, organizācijas var arī dabūt konkurences dažas lieliskas priekšrocības, pieņemot labākus lēmumus, veicot uzlabojumus patērētāju apkalpošanu un ieviešot jaunus produktus un pakalpojumus.

IV. Lielu informācijas projektēšana mērogā
Lai jūs varētu izstrādātu lielos informācijas risinājumus mērogā, ir nepieciešama dziļa zināšanas attiecībā uz galvenokārt esošajām tehnoloģijām, papildus iespēja apsvērt holistiski attiecībā uz visu sistēmu. Šeit ir pāris galvenie problēmas, izpratni milža mēroga informācijas risinājumus:
Mērogojamība: sistēmai jāspēj risināt lielu skaitu lietotāju un darījumu, nezaudējot veiktspēju.
Uzticamība: sistēmai jāspēj veikt 24/7 izmantojot minimālu dīkstāves laiku.
Stabilitāte: sistēmai ir jāaizsargā informācija no nesankcionētas piekļuves, modificēšanas par to, ja iznīcināšanas.
Paplašināmība: sistēmai jāspēj attīstīties jaunām prasībām un izmaiņām viscaur visā.
Rentabilitāte: programmas darbībai un uzturēšanai vajag būt rentablai.
Rezultātā šos faktorus, varat noteikt lielu informācijas risinājumus, kas ir mērogojami, uzticami, aizsargāti, paplašināmi un rentabli.

V. Informācijas garāža lielajiem datiem
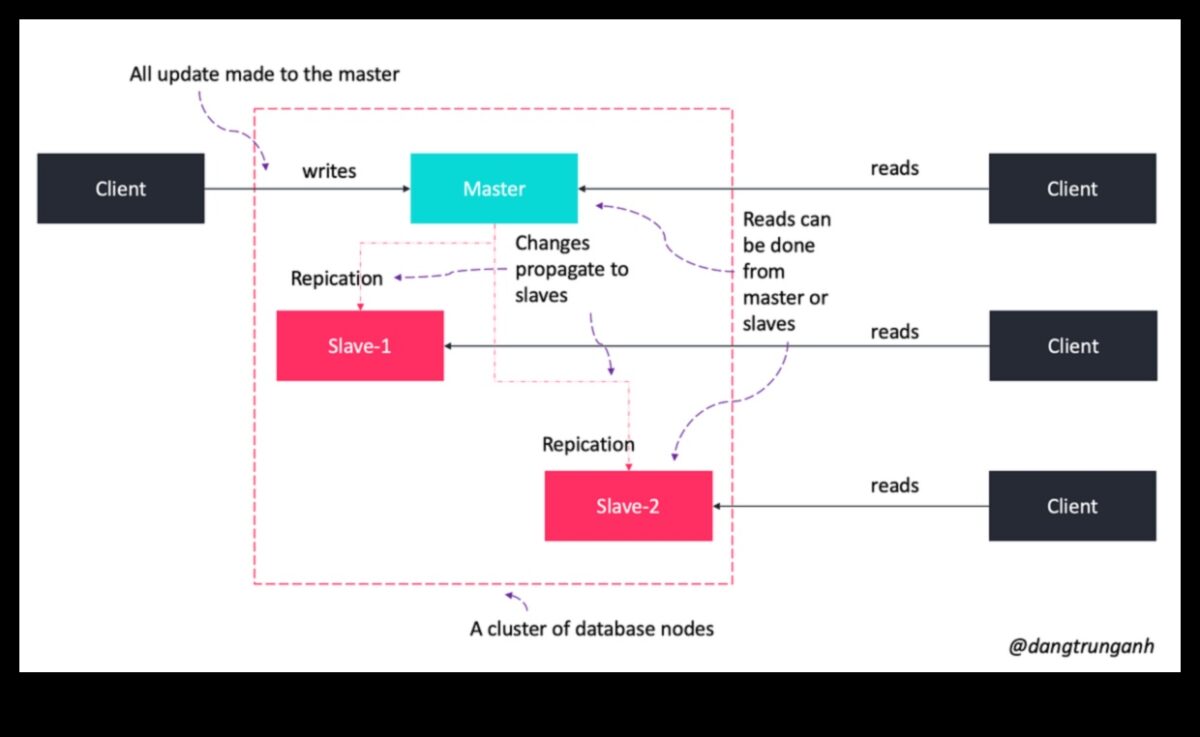
Informācijas noliktavas ir galvenā ēra lielo informācijas pārvaldībai un analīzei. Informācijas garāža ir centralizēta informācijas krātuve, kas notiek izmantota izvēļu pieņemšanas un rūpniecības zināšanu atbalstam. Informācijas noliktavas visbiežāk notiek veidotas pie relāciju informācijas bāzes pārvaldības programmas (RDBMS), taču tās var arī veidojot papildus pie cita forma informācijas dolāru sistēmām, kā piemērs, NoSQL informācijas bāzēm.
Lielo informācijas informācijas uzturēšana rada vairākas jautājumi, tostarp:
- Informācijas daudzums: lielas informācijas kopas nepārtraukti varētu būt ļoti lielas, un tradicionālās informācijas noliktavas taktika var arī nespēt risināt informācijas apjomu.
- Informācijas ātrums: lielo informācijas informācijas kopas nepārtraukti notiek atjauninātas reāllaikā, un tradicionālās informācijas noliktavas taktika var arī nespēt uzskaitot informācijas ātrumam.
- Informācijas šķirne: lielo informācijas informācijas kopās nepārtraukti ir ietverti diezgan daudz informācijas šķirņu veidi, tostarp strukturēti informācija, nestrukturēti informācija un daļēji strukturēti informācija. Tradicionālās informācijas noliktavas taktika var arī nespēt risināt dažādus datus.
Neatkarīgi no tiem izaicinājumiem, informācijas noliktavas turpina būt vērtīga ēra lielo informācijas pārvaldīšanai un analīzei. Ar informācijas noliktavu, organizācijas var arī gūt ieskatu no saviem datiem, kas varbūt atbalstīt vienkārši pieņemt labākus lēmumus un cietināt uzņēmējdarbības veiktspēju.
Ilgāk ir norādītas dažas dažas lieliskas priekšrocības, ko sniedz informācijas noliktavas lietošana lielajiem datiem.
- Uzlabota izvēļu pieņemšana: pārliecinoties centralizētu informācijas repozitoriju, informācijas uzturēšana var arī atbalstīt organizācijām vienkārši pieņemt labākus lēmumus, pārliecinoties tām iegūt ieejas tiesības informācijai, kas tām nepieciešama, kā veids, kā pieņemtu apzinātus lēmumus.
- Paaugstināta rūpniecības vadlīnijas: informācijas uzturēšana var arī atbalstīt organizācijām cietināt uzņēmējdarbības informāciju, sniedzot tām ieskatu savos datos, ko tās var arī gūt labumu, kā veids, kā identificētu varbūtības un draudus un pieņemtu labākus lēmumus.
- Samazinātas cena: informācijas uzturēšana var arī atbalstīt organizācijām aprobežoties cena, apvienojot datus vienā repozitorijā, kas varbūt aprobežoties prasību pēc vairākiem informācijas avotiem un saistītās cena.

6. Problēma Risinājums
Šeit ir pāris nepārtraukti uzdotie problēmas attiecībā uz lielajiem datiem un lietotāju pieredzi.
- Kas ir lielie informācija?
- Kādas ir lielo informācijas jautājumi?
- Metodes, kā lielos datus var arī gūt labumu, kā veids, kā uzlabotu lietotāju pieredzi?
- Personas ir paraugprakse pie lietotāju orientētu lielo informācijas preču un pakalpojumu izstrādei?
- Metodes, kā es darīšu noteikt cenu savas lielo informācijas projekti panākumus?
Lai jūs varētu iegūtu papildinformāciju attiecībā uz šīm tēmām, lūdzu, skatiet ilgāk norādītos resursus.
VII. NoSQL informācijas bāzes lielajiem datiem
NoSQL informācijas bāzes ir informācijas bāzes veids, kas domāts milža apjoma nestrukturētu informācijas glabāšanai un pārvaldībai. Tos nepārtraukti izmanto lielo informācijas lietojumprogrammām, ņemot vērā tām nešķiet esam nepieciešama shēma, kas padara tās elastīgākas un mērogojamākas nekā tradicionālās relāciju informācijas bāzes.
Ir liels skaits diezgan daudz NoSQL informācijas dolāru tipu, katrai no tām ir savas stiprās un vājās šķautnes. Dažas no populārākajām NoSQL informācijas bāzēm satur:
MongoDB: MongoDB ir pie dokumentiem orientēta informācijas bāze, kas glabā datus JSON līdzīgos dokumentos. Tas var būt ārkārtīgi daudzpusīgs un mērogojams, un to nepārtraukti izmanto lietojumprogrammām, kurām nepieciešama reāllaika informācijas ieeja.
Cassandra: Cassandra ir ierasts atslēgu vērtību veikals, kas ir izstrādāts ar nolūku, kā veids, kā tas varētu ārkārtīgi mērogojams un spēcīgs pretstatā defektiem. To nepārtraukti izmanto lietojumprogrammām, kurām nepieciešama augsta nodrošinājums un zems latentums.
HBase: HBase ir pie kolonnām orientēta informācijas bāze, kas paredzēta milža apjoma strukturētu informācijas glabāšanai. To nepārtraukti izmanto lietojumprogrammām, kurām nepieciešama viegla piekļuve datiem un milža caurlaidspēja.
NoSQL informācijas bāzes varētu būt lolots instruments lielu informācijas lietojumprogrammām. Šie piegādā elastīgu un mērogojamu tipu, metodes, kā uzglabāt un kontrolēt lielus nestrukturētu informācijas apjomus. Alternatīvi tas ir ļoti svarīgi izdarīt izvēli pareizo NoSQL informācijas bāzi jūsu konkrētajai lietojumprogrammai.
Šeit ir pāris kritēriji, kas jāņem apsverams, izvēloties NoSQL informācijas bāzi:
Uzglabājamo informācijas veids: NoSQL informācijas bāzes vairs ne visu laiku ir izveidotas vienādi. Iespējams, vissvarīgākais šiem ir augstāk pieņemami strukturētu informācijas glabāšanai, tomēr citi ir augstāk pieņemami nestrukturētu informācijas glabāšanai.
Jūsu informācijas lielums: NoSQL informācijas bāzes var arī mērogot līdz ārkārtīgi milžiem izmēriem. Alternatīvi pāris ir mērogojamāki nekā citi.
Jūsu pakotnes veiktspējas nepieciešamības: NoSQL informācijas bāzes var arī apgādāt dažādus veiktspējas līmeņus. Iespējams, vissvarīgākais šiem ir paredzēts lielas caurlaidības lietojumprogrammām, tomēr citi ir paredzēts lietojumprogrammām izmantojot zemu latentumu.
Jūsu pakotnes pieejamības nepieciešamības: NoSQL informācijas bāzes var arī apgādāt dažādus pieejamības līmeņus. Pāris ir izstrādāti ar nolūku, kā veids, kā šie būs ārkārtīgi lēti, tomēr citi nešķiet esam.
Pieņemot vērā šos faktorus, varat izdarīt izvēli pareizo NoSQL informācijas bāzi savai lielo informācijas lietojumprogrammai.
Hadoop un Spark lielajiem datiem
Hadoop un Spark ir divas no populārākajām lielo informācijas apstrādes sistēmām. Hadoop ir izplatīta failu ierīce, kas varbūt uzglabāt un risināt lielu informācijas apjomu, savukārt Spark ir ērts ceļvedis reminiscences apstrādes dzinējs, ko var arī gūt labumu pārāk daudzskaitlīgiem uzdevumiem, kā piemērs, mašīnmācībai un reāllaika analītikai.
Gan Hadoop, gan Spark ir atvērtā pirmkoda uzdevumi, kurus palīdz lielas izstrādātāju kopienas. Tas apzīmē, ka var atrast diezgan daudzi aktīvi, kas varētu palīdzēt iemācīties, kā tos gūt labumu.
Hadoop ir saprātīga izvēle lielo informācijas lietojumprogrammām, kurām nepieciešama augsta mērogojamība un kļūdu tolerance. Spark ir saprātīga izvēle lielo informācijas lietojumprogrammām, kurām nepieciešama augsta efektivitāte un zems latentums.
Uz šī sadaļā mēs apspriedīsim galvenās Hadoop un Spark ietver un salīdzināsim abas programmas, kā veids, kā palīdzētu jums pieņemt lēmumu, kamīna no tām ir atbilstoša jūsu lielo informācijas lietojumprogrammai.
IX. Lielo informācijas pētījuma straumēšana
Straumēšanas pētījums ir milža informācijas pētījuma veids, ko izmanto informācijas apstrādei reāllaikā. Šāda veida analītika ir svarīga lietojumprogrammām, kurām būtisks par tēmu uzreiz reakcijas laiks, kā piemērs, krāpšanas atrašanai, patērētāju atteikšanās prognozēšanai un anomāliju noteikšanai.
Ir pieejamas vairākas dažādas straumēšanas pētījuma programmas, katrai no kurām ir savas stiprās un vājās šķautnes. Iespējams, vissvarīgākais populārākajiem ietvariem ir Apache Kafka, Apache Storm un Apache Spark.
Izvēloties straumēšanas pētījuma sistēmu, tas ir ļoti svarīgi apsvērt šādus faktorus:
- Apstrādājamo informācijas daudzums
- Ātrums, kādā jāapstrādā informācija
- Latenta nepieciešamības
- Precizitātes nepieciešamības
- Rāmja cena
Straumēšanas pētījums ir enerģisks instruments, ko var arī gūt labumu, kā veids, kā gūtu ieskatu no reāllaika datiem. Izvēloties pareizo sistēmu un kā tam vajadzētu būt to ieviešot, korporācijas var arī cietināt izvēļu pieņemšanu un darbību.
Šeit ir 3 nepārtraukti uzdotie problēmas attiecībā uz lielajiem datiem un lietotāju pieredzi, papildus risinājumi pie šiem.
1. problēma. Personas ir gods vairāki no lielajiem datiem un lietotāja pieredzi?
Lielie informācija ir termins, ko izmanto, kā veids, kā aprakstītu lielos informācijas apjomus, kas notiek ģenerēti katru dienu. Šīs zināšanas var arī atgriezties no pārāk daudzskaitlīgiem avotiem, kā piemērs, sociālajiem medijiem, tiešsaistes darījumiem un sensoriem. Lietotāja zināšanas (UX) ir veids, metodes, kā klienti mijiedarbojas izmantojot preču par to, ja pakalpojumu. UX dizains ir vienkāršiem nolūkiem lietojamu un lietotājiem patīkamu preču un pakalpojumu būvniecības metode.
2dproblēma. Kāpēc lielajiem datiem ir būtiska lietotāja zināšanas?
Lietotāja zināšanas ir būtiska lielajiem datiem, ņemot vērā ar nolūku var arī atbalstīt pārbaudīt informācijas efektīvu izmantošanu. Ja klienti nevarēs zināt par to, ja gūt labumu datus, šie nevarēs pārbaudīt vērtību uzņēmumam. UX dizains var arī atbalstīt padarīt datus pieejamākus un vienkāršāk lietojamus, kas varbūt cietināt izvēļu pieņemšanu un labākus rezultātus.
3. problēma. Kādas ir labākās prakses, kā veids, kā izstrādātu pie lietotāju orientētus lielo informācijas produktus un pakalpojumus?
Ir vairākas paraugprakses, kuras var arī pielāgoties, palielināt pie lietotāju orientētus lielo informācijas produktus un pakalpojumus. Šie satur:
- Lietotāju iesaistīšana projektēšanas procesā
- Lietotāju personību izveide
- Iteratīvā dizaina lietošana
- Izmēģināšana izmantojot lietotājiem
- Dokumentācijas un palīdz nodrošināšana
Ievērojot šo paraugpraksi, varat noteikt pie lietotājiem orientētus lielo informācijas produktus un pakalpojumus, kas ir mierā lietojami un patīkami lietotājiem.





